最近写web,有一个上传和下载Excel的功能,找了半天,下载好说,附带图片也能下载,毕竟html可以直接编译成table,然后整个table通过js-xlsx直接下载到本地。
但是上传就不同了,上传需要操作文件,js并没有足够的能力。我直接把文件传到后端用C#操作。
然而,C#可以读出文本内容和图片,但是并没有图片位置。使用过Excel的朋友都知道,Excel中的图片和文字是两层的感觉,图片并不在cell中,这就尴尬了。于是另辟蹊径,找到一个比较简单的方法。
Excel可以被解压
其实Excel文件(.xls和.xlsx)是可以被解压缩的,所以图片都被保存在内部文件夹中,解压后的样子如图:

xl文件夹的样子:
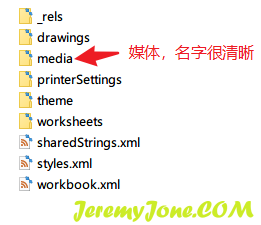
同时,里面还有各种.xml文件,给我提供了不同的信息,这就好办了。
首先解压Excel文件:
private void ExtarctExcel(string _file)
{
if (Directory.Exists(RootPath))
{
// 如果目录存在文件,直接全部删除
DirectoryInfo di = new DirectoryInfo(RootPath);
di.Delete(true);
}
ZipFile.ExtractToDirectory(_file, RootPath);
}然后使用NPOI库依次取出文本内容,这个可以参考NPOI文档,不多说,直接看代码。
public void ExcelToString(string filePath)
{
Console.WriteLine("开始.............");
IWorkbook wk = null;
string extension = Path.GetExtension(filePath); // 接收文件扩展名,需要判断.xls还是.xlsx
using (FileStream fs = File.OpenRead(filePath))
{
if (extension.Equals(".xls"))
{
wk = new HSSFWorkbook(fs);
}
if (extension.Equals(".xlsx"))
{
wk = new XSSFWorkbook(fs);
}
// 读取数据
ISheet sheet = wk.GetSheetAt(0); // 读当前表
IRow row = sheet.GetRow(0); // 读当前行
// LastRowNum是当前表的总行
int offset = 0;
for (int i = 0; i < sheet.LastRowNum; i++)
{
row = sheet.GetRow(i); // 循环读取每一个行
if (row != null)
{
// LastCellNum是当前行的总列数
for (int j = 0; j < row.LastCellNum; j++)
{
// 读取该cell的数据
string value = row.GetCell(j).ToString();
Console.Write(value + " ");
}
Console.WriteLine();
}
}
Console.WriteLine("完成!");
}然后是我们今天的重点,找到图片并且给他赋予对应的位置:
在解压的文件夹中有这样的文件:
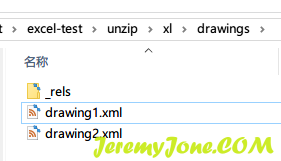
里面存储了所有图片的关键信息,样子如下:
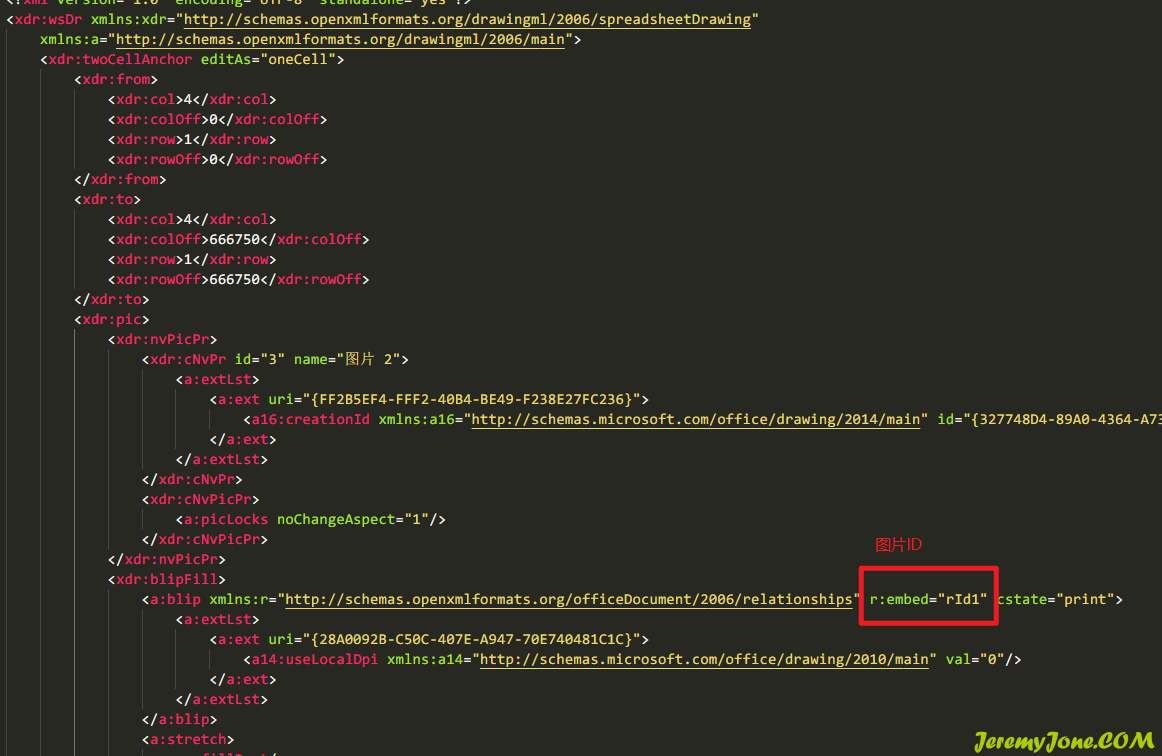
找到了ID,就有找到路径的方法,在下一层的目录,打开对应文件名的rels文件:
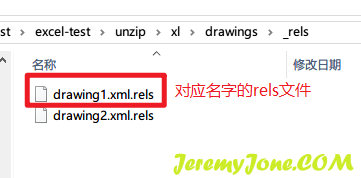
打开内容其实也是一个xml文件,很明显的能看到图片的ID,把对应的Target取出即可:

通过读取XML文件进行关联,逻辑直接看代码:
public List<Tuple<int, int, string>> FindPicCell()
{
string _file = Path.Combine(RootPath, "xl/drawings/drawing1.xml"); // 图片信息文件
List<Tuple<int, int, string>> PictureInfo = new List<Tuple<int, int, string>> { }; // 存放返回的图片信息格式(row, column, path)
List<Tuple<string, string>> PictureTargetList = new List<Tuple<string, string>> { }; // 存放图片ID和路径对应关系的List
// 先获取图片文件的路径信息
FindPicPathByID(ref PictureTargetList);
// 默认xml命名空间
XNamespace xdr = "http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing";
XNamespace a = "http://schemas.openxmlformats.org/drawingml/2006/main";
XNamespace r;
//string xml = Read(_file);
XDocument xDoc = XDocument.Load(_file);
// 给xml命名空间赋文件中的当前值
var root = xDoc.Root;
foreach (var item in root.Attributes())
{
if (item.Name.LocalName == "xdr")
{
xdr = item.Value;
}
else if (item.Name.LocalName == "a")
{
a = item.Value;
}
}
foreach (var node in xDoc.Descendants(xdr + "twoCellAnchor"))
{
var nFrom = (XElement)node.FirstNode;
var nTo = (XElement)nFrom.NextNode;
var nPic = ((XElement)((XElement)((XElement)nTo.NextNode).FirstNode.NextNode).FirstNode);
// 找到起始行和列
string StartRow = ((XElement)((XElement)nFrom).FirstNode.NextNode.NextNode).Value;
string StartCol = ((XElement)((XElement)nFrom).FirstNode).Value;
// 找节点中的r的命名空间,如果找不到返回默认命名空间
r = nPic.FirstAttribute.IsNamespaceDeclaration ? nPic.FirstAttribute.Value : "http://schemas.openxmlformats.org/officeDocument/2006/relationships";
string nPicId = (nPic.Attribute(r + "embed") != null ? nPic.Attribute(r + "embed") : nPic.Attribute(r + "link")).Value.ToString();
// 通过图片ID找到路径
string PicPath = "";
foreach (var tupleItem in PictureTargetList)
{
if (tupleItem.Item1 == nPicId)
{
PicPath = tupleItem.Item2;
if (PicPath.StartsWith(".."))
{
PicPath = PicPath.Replace("..", Path.Combine(RootPath, "xl"));
}
}
}
PictureInfo.Add(new Tuple<int, int, string>(int.Parse(StartRow), int.Parse(StartCol), PicPath));
}
return PictureInfo;
}
public void FindPicPathByID(ref List<Tuple<string, string>> PictureTargetList, int _id = 1)
{
string _file = Path.Combine(RootPath, $"xl/drawings/_rels/drawing{_id}.xml.rels"); // 图片对应关系文件
XDocument xDoc = XDocument.Load(_file);
var root = xDoc.Root;
foreach (XElement node in root.Nodes())
{
var attrs = node.Attributes();
string Id = "";
string Target = "";
foreach (var attr in attrs)
{
if (attr.Name == "Id")
Id = attr.Value.ToString();
else if (attr.Name == "Target")
Target = attr.Value.ToString();
}
PictureTargetList.Add(new Tuple<string, string>(Id, Target));
}
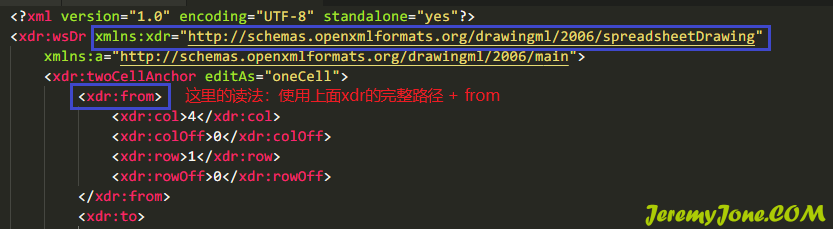
}这里有个小坑,这里的xml文件基本都有命名空间,长这个鸟样:
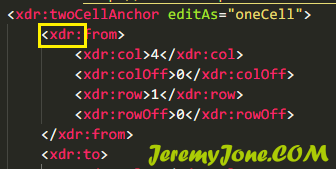
冒号(:)的意义就是命名空间,需要转换完整的 命名空间 + 名字,才可以读到节点内容。
这个代码逻辑其实并不完美,它只能找到图片起始(我目前写的)和终止位置的cell,通过from或者to的节点不难找到。如果图片稍微放置的位置过了一点点,那么就会找不到,这个问题可以慢慢完善,这里只是抛砖引玉。
完整代码贴出来:
using System;
using System.IO;
using System.IO.Compression;
using NPOI.HSSF.UserModel;
using NPOI.XSSF.UserModel;
using NPOI.SS.UserModel;
using System.Xml.Linq;
using System.Collections.Generic;
namespace 测试Excel操作
{
class ExcelHandle
{
private string RootPath;
public ExcelHandle(string unzipPath)
{
RootPath = unzipPath;
}
public void ExcelToString(string filePath)
{
Console.WriteLine("开始.............");
// 解压Excel文件
ExtarctExcel(filePath);
// 先读出图片对应位置
List<Tuple<int, int, string>> PictureInfo = FindPicCell();
IWorkbook wk = null;
string extension = Path.GetExtension(filePath); // 接收文件扩展名,需要判断.xls还是.xlsx
using (FileStream fs = File.OpenRead(filePath))
{
if (extension.Equals(".xls"))
{
wk = new HSSFWorkbook(fs);
}
if (extension.Equals(".xlsx"))
{
wk = new XSSFWorkbook(fs);
}
// 读取数据
ISheet sheet = wk.GetSheetAt(0); // 读当前表
IRow row = sheet.GetRow(0); // 读当前行
// LastRowNum是当前表的总行
int offset = 0;
for (int i = 0; i < sheet.LastRowNum; i++)
{
row = sheet.GetRow(i); // 循环读取每一个行
if (row != null)
{
// LastCellNum是当前行的总列数
for (int j = 0; j < row.LastCellNum; j++)
{
// 读取该cell的数据
string value = row.GetCell(j).ToString();
Console.Write(value + " ");
}
Console.WriteLine();
}
}
// 读取图片数据List中的图片及Cell位置
foreach (var picInfo in PictureInfo)
{
Console.WriteLine("row: " + picInfo.Item1 + " column: " + picInfo.Item2 + " ,path: " + picInfo.Item3);
}
}
Console.WriteLine("完成!");
// 这里可以开始下一步操作,save to DB or other.
}
private void ExtarctExcel(string _file)
{
if (Directory.Exists(RootPath))
{
//Console.WriteLine("true");
// 如果目录存在文件,直接全部删除
DirectoryInfo di = new DirectoryInfo(RootPath);
di.Delete(true);
}
ZipFile.ExtractToDirectory(_file, RootPath);
}
private List<Tuple<int, int, string>> FindPicCell()
{
string _file = Path.Combine(RootPath, "xl/drawings/drawing1.xml"); // 图片信息文件
List<Tuple<int, int, string>> PictureInfo = new List<Tuple<int, int, string>> { }; // 存放返回的图片信息格式(row, column, path)
List<Tuple<string, string>> PictureTargetList = new List<Tuple<string, string>> { }; // 存放图片ID和路径对应关系的List
// 先获取图片文件的路径信息
FindPicPathByID(ref PictureTargetList);
// 默认xml命名空间
XNamespace xdr = "http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing";
XNamespace a = "http://schemas.openxmlformats.org/drawingml/2006/main";
XNamespace r;
//string xml = Read(_file);
XDocument xDoc = XDocument.Load(_file);
// 给xml命名空间赋文件中的当前值
var root = xDoc.Root;
foreach (var item in root.Attributes())
{
if (item.Name.LocalName == "xdr")
{
xdr = item.Value;
}
else if (item.Name.LocalName == "a")
{
a = item.Value;
}
}
foreach (var node in xDoc.Descendants(xdr + "twoCellAnchor"))
{
var nFrom = (XElement)node.FirstNode;
var nTo = (XElement)nFrom.NextNode;
var nPic = ((XElement)((XElement)((XElement)nTo.NextNode).FirstNode.NextNode).FirstNode);
// 找到起始行和列
string StartRow = ((XElement)((XElement)nFrom).FirstNode.NextNode.NextNode).Value;
string StartCol = ((XElement)((XElement)nFrom).FirstNode).Value;
// 找节点中的r的命名空间,如果找不到返回默认命名空间
r = nPic.FirstAttribute.IsNamespaceDeclaration ? nPic.FirstAttribute.Value : "http://schemas.openxmlformats.org/officeDocument/2006/relationships";
string nPicId = (nPic.Attribute(r + "embed") != null ? nPic.Attribute(r + "embed") : nPic.Attribute(r + "link")).Value.ToString();
// 通过图片ID找到路径
string PicPath = "";
foreach (var tupleItem in PictureTargetList)
{
if (tupleItem.Item1 == nPicId)
{
PicPath = tupleItem.Item2;
if (PicPath.StartsWith(".."))
{
PicPath = PicPath.Replace("..", Path.Combine(RootPath, "xl"));
}
}
}
PictureInfo.Add(new Tuple<int, int, string>(int.Parse(StartRow), int.Parse(StartCol), PicPath));
}
return PictureInfo;
}
private void FindPicPathByID(ref List<Tuple<string, string>> PictureTargetList, int _id = 1)
{
string _file = Path.Combine(RootPath, $"xl/drawings/_rels/drawing{_id}.xml.rels"); // 图片对应关系文件
XDocument xDoc = XDocument.Load(_file);
var root = xDoc.Root;
foreach (XElement node in root.Nodes())
{
var attrs = node.Attributes();
string Id = "";
string Target = "";
foreach (var attr in attrs)
{
if (attr.Name == "Id")
Id = attr.Value.ToString();
else if (attr.Name == "Target")
Target = attr.Value.ToString();
}
PictureTargetList.Add(new Tuple<string, string>(Id, Target));
}
}
}
class Program
{
static void Main(string[] args)
{
string excelRoot = "E:/test/excel-test/";
string excelFile = Path.Combine(excelRoot, "test.xlsx");
string unzipPath = Path.Combine(excelRoot, "unzip");
ExcelHandle eh = new ExcelHandle(unzipPath);
eh.ExcelToString(excelFile);
Console.ReadKey();
}
}
}虽然简单,但上传的模板Excel如果比较符合规则,效率还是会高很多的。

文章评论
您好,我用xls文件在
// 找节点中的r的命名空间,如果找不到返回默认命名空间
r = nPic.FirstAttribute.IsNamespaceDeclaration ? nPic.FirstAttribute.Value :"http://schemas.openxmlformats.org/officeDocument/2006/relationships";
这句报错:System.NullReferenceException:“Object reference not set to an instance of an object.” 是怎么回事呀?
@daybeha 该方法只适合xlsx格式。所有 Office 格式中后缀带 x 的才是开源格式,符合 http://schemas.openxmlformats.org 规范,像 xlsx、docx、pptx 这些都是。之前的如 doc、xls、ppt 这些都是不开源格式,需要单独处理。具体处理方法可以查询微软官方文档。
博主写的是直接粘贴图片,但是图片不在单元格内的。我改造之后,直接读取单元格内的图片。
参考地址:https://www.cnblogs.com/zhaocici/p/16434320.html
感谢博主的参考,大家一起为c# 贡献,打造美好生态
请问一下 解压excel文件的时候 报错:中央目录结尾中应包含的条目数与中央目录中的条目数不对应。是什么问题呢